



pitch, tone, timbre, rhythm, inflection, and emphasis among others,
which—during the act of listening—leave us with impressions about the speaker that go beyond content and context as well as the mere level of sound. The only problem is: the human voice is a fleeting thing, which makes it virtually impossible to measure and analyze the interplay between all of those parameters in real-time. Not so with pre-recorded speech, of course, which provides researchers with a potent avenue to capture and visualize the dynamic interplay of parameters that shape the human voice, and the way it is perceived.
To be honest, however, up until a week ago, that topic had never really crossed my mind. But then I had my first couple of SIF meetings, and I am now working on a project designed to find (better), more innovative ways of visualizing prerecorded voices along a set of specific parameters, enabling researchers to export parameter-related data for quantitative as well as qualitative analysis. How fascinating is that?!
I have put “better” in parentheses here for a reason because there are already quite a number of programs available that do just that.
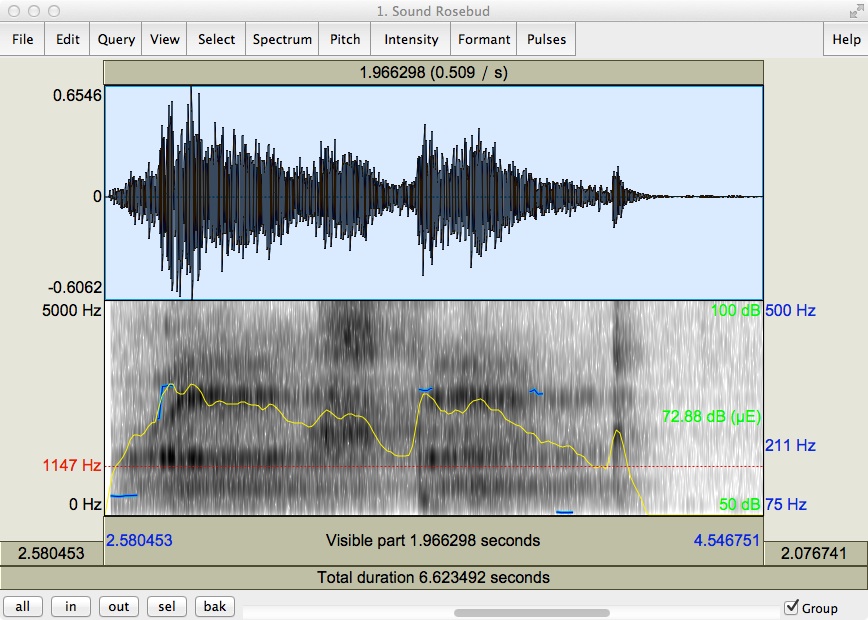
What you see above is a screenshot I have taken with the free software, Praat (click the link to download). Whit this little tool, one can not only record mono and stereo sounds, one can also load pre-recorded sounds in order to visualize a couple of the kinds of parameters that I’ve listed above. The sound I have chosen for this example is a word, and it’s probably one of the most enigmatic utterances in cinematic history: “Rosebud” from the movie Citizen Kane (1941). The main character, Charles Foster Kane, utters this word with his last breath, and throughout the movie, audiences ponder not only the meaning of but also Kane’s relationship to the word. I don’t want to give away any spoilers because it’s such a great movie, but what I can reveal is that Kane is fond of what “Rosebud” refers to. Now, moving back to the image, what if there was a way to visualize vocal parameters in such a way as to draw relatively accurate inferences about the emotional quality of different types of utterances.
What we can visualize with Praat, first and foremost, is a waveform in the upper half, and the amplitudes here tell us something about the volume and the emphasis of the utterance. Where things become more interesting, however, is when we look at the lower half of the image. Here, we have access to visualization of certain sound-related parameters such as pitch (marked in blue) and intensity (marked in yellow). Applications like Praat are commonly used in the field of speech therapy.
Current research on sound visualization is trying to capture vocal expression on a quantitative as well as qualitative basis. Here is just one interesting paper on the topic in which the authors are “particularly interested in the paralingual (pich, rate, volume, quality, etc.), phonetic (sound content), and prosodic (rhythm, emphasis, and intonation) qualities of voice” (157): “Sonic Shapes: Visualizing Vocal Expression.”
And this is one of the projects that I’m going to work on this semester. Again, up until a week ago, those questions really hadn’t crossed my mind. But this is what it means to be a SIF fellow at Georgia State, I guess. Not only do you get to start working with a group of very smart people, you are also being confronted with new things, new questions, and new ways of seeing. And if all goes well, you eventually start looking for even newer and more exciting things yourself that you’re eager to share with others.
Speaking of sharing, I want to make it a habit of always ending a post with something worth checking out. So, if you haven’t seen Citizen Kane, yet, then by all means, do so!
Thomas Breideband