Ground Rules for Gene Expression
(AKA Central Dogma)
Central Dogma, in the broadest sense, encompasses the genetic mechanisms of Replication, Translation and Translation. In the strictest sense, Central Dogma describes gene expression: Information encoded in the nucleotides of DNA being use to construct proteins. The two core genetic processes involved in gene expression are Transcription (synthesis of RNA) and Translation (synthesis of proteins).
 |
| Central Dogma of Biology |
Before digging into each process, let’s talk a little about what is at stake here. DNA holds our genetic history. It holds codes on how to build an organism, but what does that really mean?
The basic unit of life is the cell, and cells are formed from phospholipids can naturally form bilayers. Furthermore, phospholipids can even naturally form spherical structures that create two fluid compartments, outside vs. inside. The phospholipids that make up the cellular membrane form the most basic feature of the cell: a dividing point, separating the inside from the outside (more on this in the weeks to come).

Membranes though are passive. As a selectively permeable barrier, only certain materials can cross. Proteins add functionality to the membrane. By embedding proteins, you can change the permeability of the membrane. This is how cells balance what is on the inside, and what is on the outside. Membrane proteins can also have enzymatic or signal functions. Proteins add functionality to the membrane.
A common expression is that DNA holds the code to make an organism. The meaning of this phrase lies in the concept that by making proteins, we make phospholipid membranes and cells functional. From DNA, cells can build proteins for metabolic pathways, to produce various chemical compounds, anchor with other cells, and in multicellular complex life, we even have the development of special cellular roles that work together to form a composite whole.
The concept of how we go from DNA to RNA and then Proteins is one of the most critical concepts in biology! Today we are going to focus on some of the basics, the Ground Rules, of genetics.
All genetic processes work due to base complementarity. If you know the base complementarity rules, then the foundations of genetics will make sense. At times, this may seem repetitious, but I really want you to get these terms and concepts.
Genes are sometimes referred to as the unit of heredity, and with good reason. A gene is a segment of DNA that holds the code to make a protein  (NOTE: or functional RNA, such as transfer RNA). In modern biology, we refer to gene products, which are just the expressed macromolecules coded by a gene.
(NOTE: or functional RNA, such as transfer RNA). In modern biology, we refer to gene products, which are just the expressed macromolecules coded by a gene.
Remember, a gene product can be either protein or functional RNA (e.g., tRNA). Functional RNA does not code for proteins, instead, these RNA strands have some function in cellular metabolism, most notably in the genetic process of Translation. Examples include transfer RNA (tRNA), ribosomal RNA (rRNA), and small nuclear RNA (snRNA).
All genes have non-coding portions that are critical for the correct transcription (synthesis of RNA). These non-coding areas are critical for regulation and aligning the transcription enzymes (e.g., RNA polymerase). Below is a graphic that shows the structure of a gene. The promoter of a gene is a sequence of DNA upstream of the actual code (coding region) that indicates the “Start” point for transcription. This is how your cell knows where to begin transcription. The loss of the promoter means that the gene will no longer be expressed.
In Eukaryotic cells, a common promoter is a DNA sequence that reads TATAAA and is better known as the
TATA-Box. In bacteria, the promoter is known as the
Pribnow Box (Pribnow-Schaller box). In both cases, the promoter is found in the
Major Groove of the DNA

molecule. As can be seen in the image to the right, the major groove is wide enough to “see” the base pairs. The base pairs have an electrochemical profile, and thus can respond to other chemicals (via van Der Waals forces). Thus,
the major groove is a place where proteins (and other compounds) can bind to specific sequences of DNA! The promoter sequences are found in the major groove.
 - Scaled (0%). Available at: http://deliciouslygrey.files.wordpress.com/2011/10/pdbimportvisualization2.png?w=300&h=300. Accessed October 29, 2012.")
The image to the right shows a bacterial promoter event. One of the factors needed to start transcription (by recognizing the promoter) has bound into the major groove. This recognition event is needed to identify the start point of a gene. The Transcription Initiation Complex will then begin to form at this site and begin the transcription of the gene.
Many genes are regulated, meaning they can be turned on and off. Beyond a promoter, a regulated gene will typically have a non-coding region known as the
Operator. The operator is located downstream of the promoter (meaning it will be between the promoter and the coding region). Regulatory proteins can bind to the operator, preventing transcription. Remember, cells are masters at energy conservation. They will not begin producing proteins that are unnecessary. Gene regulation is a common activity of
Signal & Receptor systems. The image below is a good visual of the promoter & operator systems.
. Available at: http://universe-review.ca/I11-37-operon.jpg. Accessed October 29, 2012.")
Housekeeping genes are those that are needed for the general function of the cell and can include genes for glycolysis, citric acid cycle, and ribosomes. These genes are always ON, and are referred to as
constitutive genes.
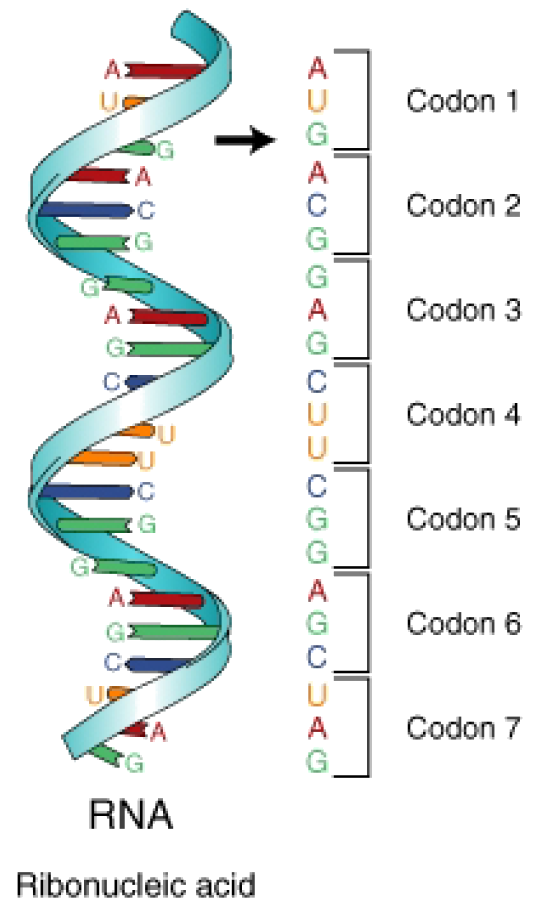
Messanger RNA (mRNA) is a molecule of RNA that cares the gene code for the construction of a protein. mRNA is sent to the Ribosome in order to produce a protein. The code for constructing a protein is in Nucleotide Language, meaning the code is a code of nucleotides. Specifically, the code in mRNA is in the ribonucleotide language (A, U, G, C). In order to make a protein, it is necessary to Translate the ribonucleotide language into the language of proteins, i.e., amino acid sequences.
In order to translate, you need an agent of translation. This agent of translation must be a molecule that contains both ribonucleotides and amino acids (think of it as the nucleotide-amino acid dictionary). A specific ribonucleotide sequence must directly correspond to an amino acid, just as in translating human languages requires a word for word relationships. This concept of a direct nucleotide to amino acid relationship is the basis of the Genetic Code.
. Available at: http://3.bp.blogspot.com/-CcuK-nFsLYY/T3D28-qanLI/AAAAAAAAAHY/G99nt_DpF_0/s1600/Transfer+RNA.jpg. Accessed October 29, 2012.")
The agent of translation is
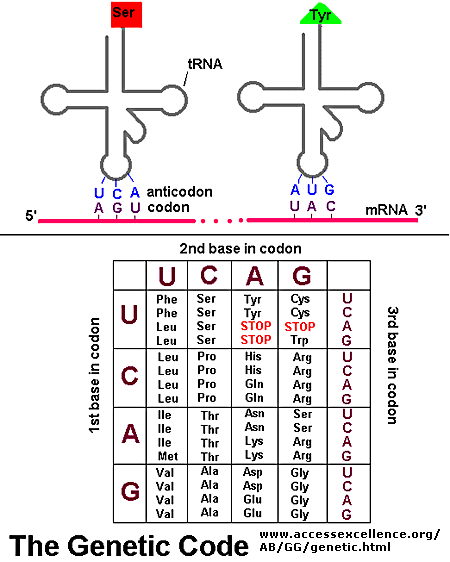
Transfer RNA (tRNA). In tRNA, there is a direct physical correspondence between a 3 nucleotide sequence (anti-codon) and an amino acid. To the right are common ways of illustrating tRNA, with the 3
rd image being the most common way of drawing the molecule. In the image, each molecule has a region known as the anticodon; this region will interact with mRNA. At the 3′ end of the molecule, a specific amino acid will be bound.
On the mRNA, the code is broken down into codons (think of these as genetic words). Codons consist of 3 adjacent nucleotides. Codons are complimentary to anticodons found on tRNA. Each tRNA has a specific anticodon-amino acid relationship, so each codon then specifies an amino acid. The genetic code is NOT ambiguous. There is a direct correspondence between codon and amino acid; the tRNAs make sure of this.
The ribonucleic language is divided into 64 3-nucleotide words known as codons. Condons specify though tRNA an amino acid. The Genetic Code is thus the translation scheme between codons and amino acids. [NOTE: another way to describe the genetic code is in terms of a computer algorithm]. Below is a rather unique way of viewing the genetic code. It is an excellent way of visualizing the number of redundancies in the code.
The genetic code is redundant, which means that there are multiple codons (3 nucleotides) that specify the same amino acid. For example, around the 12 o’clock position of the above chart, you see the amino acid glycine. The codons GGU, GGC, GGA and GGG all specify Glycine. Phenylalanine is specified by UUU and UUC. There are only a few amino acids, such as methionine, that are specified by a single codon (in the case of methionine it is AUG).
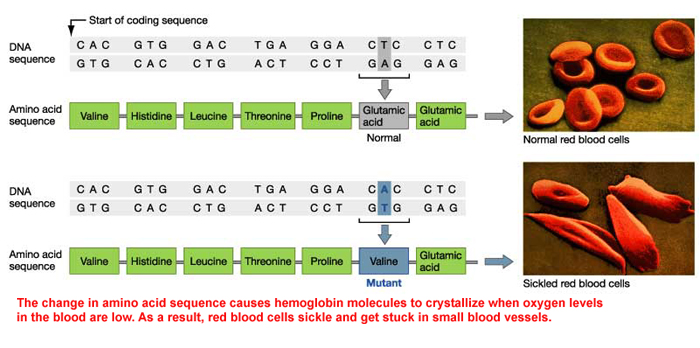
The presence of redundancies means that some alterations in the gene sequence are silenced (silent mutation). For example, changing GGU to GGA does not change the specified amino acid (Glycine). This is a silent mutation. Changing UUC to UUA may cause a problem (point mutation), but both Leucine and Phenylalanine are hydrophobic, so the variation may be minor. Chaing CAC to CAG though has more impact as you are changing the positive histidine to a polar glutamine (you lose the full positive charge of histidine). Remember, changing amino acids can easily change the way a protein folds. REMEMBER: The genetic code has redundancies, which will limit some problems with mutations.
Below is a more classic way to represent the genetic code, in the form of a table. The way the table is arranged, you can easily see the various redundancies in the system. In both representations, notice that there are three codons that specify STOP. These stop codons, UAA, UAG, and UGA are essential for the termination of protein synthesis. In the image below, you will notice AUG has been tagged as the initiation (start) codon. All protein synthesis begins with the code AUG. We will talk more about this later in the week.
. Available at: http://bio3400.nicerweb.com/Locked/media/ch13/13_07-genetic_code.jpg. Accessed October 29, 2012.")
Daily Challenge
Today helps to set the stage for our discussion of the central dogma of biology (gene expression). In reading, you find that DNA holds the codes to make various types of RNA and Proteins. Most of the time, what concerns us is the production of proteins, as they will add functionality to our cells.
At the heart of the Central Dogma is the genetic code. This code shows how you move from the language of nucleic acids to the language of proteins (aka, amino acids). This code is Universal and Non-Ambiguous, but what does that mean? Your goal today is to read, in your text and in the optional reading, and reflect on the concept of gene expression and the genetic code. Why is it so important? How do we use it? How does this influence concepts from understanding hormonal changes at puberty, evolution and genetic engineering?









{kind=link}