
One of the most well studied gene regulation systems is the Lac Operon found in Escherichia coli. To understand this system, it is important to first understand that bacteria do not experience Transcription and Translation in exactly the same way as eukarotes (the mechanics are very similar, but there are some distinct differences).
The core difference between prokaryotes and eukaryotes is the nucleus. Since bacteria lack a nucleus, transcription takes place in the cytosol. There is no need for a tag to get out of the nucleus, so there is no need for capping. Also, there are no introns, so no need for splicing. Basically, there is no processing of RNA to make mRNA. There is no pre-mRNA. When a gene is transcribed, the transcript is mRNA. - Scaled (73%). 2012. Available at: http://barleyworld.org/sites/default/files/figure-08-01_0.jpg. Accessed November 6, 2012.")
Since there is no membrane separating transcription from translation, you can couple these to processes. As mRNA is made, it can be translated (polyribosome).
Bacteria have a single circular molecule of DNA (a genophore, not a chromosome). They have to conserve their genetic space, so bacteria combine genes for a metabolic process in a single mRNA. IMPORTANT: bacteria can combine genes for a metabolic pathway into a sequential sequence with a single promoter. Thus, when you transcribe, you get all the genes for a given metabolic pathway.
The word OPERON describes this unique arrangement of prokaryotic genes: One promoter and one operator for a given series of metabolically linked genes.. Available at: http://upload.wikimedia.org/wikipedia/commons/4/48/Lac_operon1.png. Accessed November 6, 2012.")
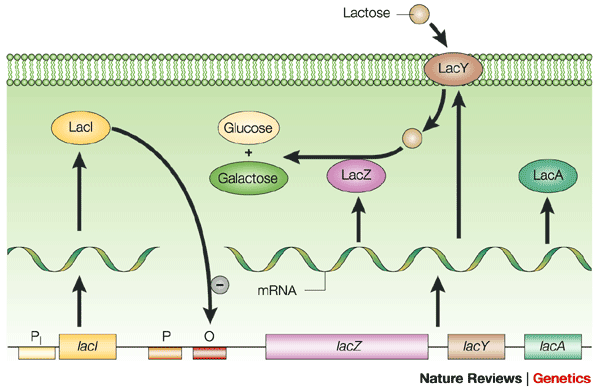
The lac Operon holds three genes that give the cell the ability to take in and use the sugar LACTOSE. [Image Note: Bacteria have two promoter regions, -10 & -35, for a given gene or operon]
For E. coli, glucose is the preferred sugar. When glucose is present, there is no need to use lactose: these genes are not transcribed. When there is no glucose, E. coli has to use other sugars. IF lactose is present, the genes for lactose utilization will be made. Conversely, if there is no lactose, they genes remain locked down.
- Glucose Present: No transcription
- Glucose Absent: Minimal transcription
- Glucose Absent, Lactose Present: Transcription of the lac operon.
NOTE: In this example, there are two ways to control the expression of a gene or operon:
- You can block the operator of the gene. This prevents RNA polymerase from making RNA.
- You can alter the promoter (or the interaction between transcription factors and DNA) to prevent binding of the Transcription Complex (RNA polymerase).
Negative Transcription Regulation (Repression) in the lac operon: There is a repressor for the lac operon. This is a protein that can bind to the operator of the lac operon (that region immediately downstream from the promoter). This creates a physical block that prevents RNA polymerase from transcribing.
The lac operon repressor (LACI) is a protein that is constitutively (always) expressed. This indicates that the lac operon is normally turned OFF. Notice that the gene for the regulatory protein is upstream from the lac operon. The lac repressor (LacI) binds to the major groove of the DNA at the operator. As you can see in the annotated image of the repressor, you have a DNA-binding region (active site), and a regulatory domain. The regulatory domain has the ability to bind to Lactose (the inducer).
 You must have a way to unlock the operon, or to put it another way, to inactivate the repressor. An inducer is a ligand that can bind to a regulatory domain, changing the shape of the regulatory domain, and thus inactivating the DNA-binding domain. In the case of the the lac repressor, the ligand is allolactose (a derivative of lactose). When allolactose binds to the lac repressor, the repressor is inactivated, and the operon cleared. This is seen in the image below.
You must have a way to unlock the operon, or to put it another way, to inactivate the repressor. An inducer is a ligand that can bind to a regulatory domain, changing the shape of the regulatory domain, and thus inactivating the DNA-binding domain. In the case of the the lac repressor, the ligand is allolactose (a derivative of lactose). When allolactose binds to the lac repressor, the repressor is inactivated, and the operon cleared. This is seen in the image below.
Therefore, the lac operon is partially regulated by the presence of lactose in the environment. If there is no lactose in the environment, then there is no need to transcribe the three genes needed to use lactose.

Remember, we don’t want to expend energy for things we don’t need. Below is the size of the three gene products:
- β-Galactosidase 1,024 Amino Acids
- β-Galactoside Permease 418 Amino Acids
- β-galactoside transacetylase 203 Amino Acids
Total Amino Acids, 1645. Using the assumption of 4 ATP per amino acid added to a protein, that makes 6580 ATPs needed just for protein synthesis. With this many amino acids, you are also looking at 4935 nucleotides (remember 3 nucleotides = codon = 1 amino acid), plus at least 3 stop codons. Each nucleotide added to a transcript takes the equivalent of 1 ATP, so you are looking at 4944 ATP minimum to make the transcript. Just to make one example of each protein (gene product), you are looking at 11,524 ATP. Do you just make one example of each protein? NO! Do you have though the idea that this is energy consumptive? Would you make it if there was no lactose around?
Tomorrow we will look at the positive regulation of the lac operon. Remember, you still will not transcribe this operon if glucose is present. You only transcribe when glucose is absent. So how does the operon know when glucose is absent? That will be our discussion tomorrow.
Daily Challenge
In your own words, describe how lactose (allolactose) is used to regulate the transcription of the lac operon. In your discussion, make sure that you explain the concept of an operon, and discuss the differences between eukaryote and prokaryote gene transcription.




 molecule. As can be seen in the image to the right, the major groove is wide enough to “see” the base pairs. The base pairs have an electrochemical profile, and thus can respond to other chemicals (via van Der Waals forces). Thus,
molecule. As can be seen in the image to the right, the major groove is wide enough to “see” the base pairs. The base pairs have an electrochemical profile, and thus can respond to other chemicals (via van Der Waals forces). Thus,  - Scaled (0%). Available at: http://deliciouslygrey.files.wordpress.com/2011/10/pdbimportvisualization2.png?w=300&h=300. Accessed October 29, 2012.") The image to the right shows a bacterial promoter event. One of the factors needed to start transcription (by recognizing the promoter) has bound into the major groove. This recognition event is needed to identify the start point of a gene. The Transcription Initation Complex will then begin to form at this site, and begin the transcription of the gene.
The image to the right shows a bacterial promoter event. One of the factors needed to start transcription (by recognizing the promoter) has bound into the major groove. This recognition event is needed to identify the start point of a gene. The Transcription Initation Complex will then begin to form at this site, and begin the transcription of the gene.. Available at: http://universe-review.ca/I11-37-operon.jpg. Accessed October 29, 2012.") House keeping genes are those that are needed for the general function of the cell, and can include genes for glycolysis, citric acid cycle, and ribosomes. These genes are always ON, and are referred to as
House keeping genes are those that are needed for the general function of the cell, and can include genes for glycolysis, citric acid cycle, and ribosomes. These genes are always ON, and are referred to as . Available at: http://2.bp.blogspot.com/-i-CYqAFf61o/TZXYoBQmXrI/AAAAAAAAB5g/5PmMdfOP1PQ/s1600/genetic-code-1.jpg. Accessed October 29, 2012.")
. Available at: http://bio3400.nicerweb.com/Locked/media/ch13/13_07-genetic_code.jpg. Accessed October 29, 2012.")


. Available at: http://upload.wikimedia.org/wikipedia/commons/thumb/d/d5/X_dominant_affected_mother.svg/200px-X_dominant_affected_mother.svg.png. Accessed October 18, 2012.")



. Dihybrid cross.png. Found at http://en.wikipedia.org/wiki/File:Dihybrid_cross.png, accessed on October 17, 2012.")
 Alleles. Found at http://www.bbc.co.uk/schools/gcsebitesize/science/add_aqa_pre_2011/celldivision/inheritance1.shtml, accessed on October 16, 2012")
. Genetics, Probabilty and Chance. Found at http://www.biology.iupui.edu/biocourses/N100/2k4ch10genetics.html, accessed on October 16, 2012.")
. Genetics, Probabilty and Chance. Found at http://www.biology.iupui.edu/biocourses/N100/2k4ch10genetics.html, accessed on October 16, 2012.")
. Punnett square mendel flowers.svg. Found at http://en.wikipedia.org/w/index.php?title=File:Punnett_square_mendel_flowers.svg&page=1, accessed on October 16, 2012.") An easy way to view these possible outcomes is to use a Punnett square, a simple visual probability tool. The square shown to the right demonstrates the inheritence (genotype and phenotype) probability of pea flower color. On the left hand side of the square you will see the female (pistil) allelic contribution, and on top the male (pollen) allelic contribuition. The mother can donate either B or b; the father can donate either B or b.
An easy way to view these possible outcomes is to use a Punnett square, a simple visual probability tool. The square shown to the right demonstrates the inheritence (genotype and phenotype) probability of pea flower color. On the left hand side of the square you will see the female (pistil) allelic contribution, and on top the male (pollen) allelic contribuition. The mother can donate either B or b; the father can donate either B or b.
. Available at: http://upload.wikimedia.org/wikipedia/commons/thumb/e/e4/DNA_chemical_structure.svg/206px-DNA_chemical_structure.svg.png. Accessed October 25, 2012.") DNA is a double stranded molecule, in which the strands are anti-parallel. This means that one strand starts at the 5′ end
DNA is a double stranded molecule, in which the strands are anti-parallel. This means that one strand starts at the 5′ end 
. Available at: http://www.bio.miami.edu/dana/pix/phosphodiester.jpg. Accessed October 25, 2012.") At this point, the critical thing to remember is that DNA Polymerase will need a free 3′ end on which to add a new nucleotide.
At this point, the critical thing to remember is that DNA Polymerase will need a free 3′ end on which to add a new nucleotide. - Scaled (0%). Available at: http://25.media.tumblr.com/tumblr_mbs7jp80441qc0hbao1_1280.jpg. Accessed October 25, 2012.") The image above shows the leading and lagging strand. Notice that the leading strand is replicating toward the
The image above shows the leading and lagging strand. Notice that the leading strand is replicating toward the