Hi everyone,
Today’s post will mostly be interesting for those of you who have an interest in audio post-production especially when it comes to dealing with the kinds of unwanted issues that ‘pop up’ during the recording process (pun intended, more on this later).
The projects I am currently working on is about creating and curating a number of video interviews to promote hybrid pedagogy (some also call it blended learning) and provide advice for faculty and students who want to try out hybrid forms of teaching and learning.
While the visual material has already been cut, there are still a couple of issues as far as the audio is concerned. As our interview videos will consist of both voice and background, we need to find a proper balance between the two. That means that some level adjustment is in order. Besides that, we will have to deal with some unwanted noise that found its way into the recording, the humming of the air conditioning for example. So, what I am going to do now is run you through the way I am dealing with these kinds of problems.
Before we begin, here is a quick and dirty run-down of the steps involved in processing audio for the video: cleaning and consolidating tracks, level adjustments, filtering out unwanted background noises, compressing, and limiting. All of those steps I applied to the vocal performances.
On a side note, the software I am using for this project is Pro Tools. However, since all of these tasks are basic elements of mixing, they can also be accomplished with other available software that’s currently on the market such as Logic Pro, Cubase, Ableton Live, or GarageBand.
Before we begin, if you interested in learning more about audio recording, mixing, and post-production then check out the tutorial videos on Lynda.com. Georgia State University has access to the entire Lynda catalog of videos. You can use your campusID and password to sign in. Once you have access, I suggest you check out the following videos: “Audio Mixing Bootcamp,” “Foundations of Audio: EQ and Filters,” and “Foundations of Audio: Compression and Dynamic Processing.”
1. Cleaning up and Volume Adjustments
Below you see my point of departure. I started out with a total of four tracks. From top to bottom: the video track, a reference track that contains speech as well as music, then a track that contains all the interview bits, and finally the background music track.
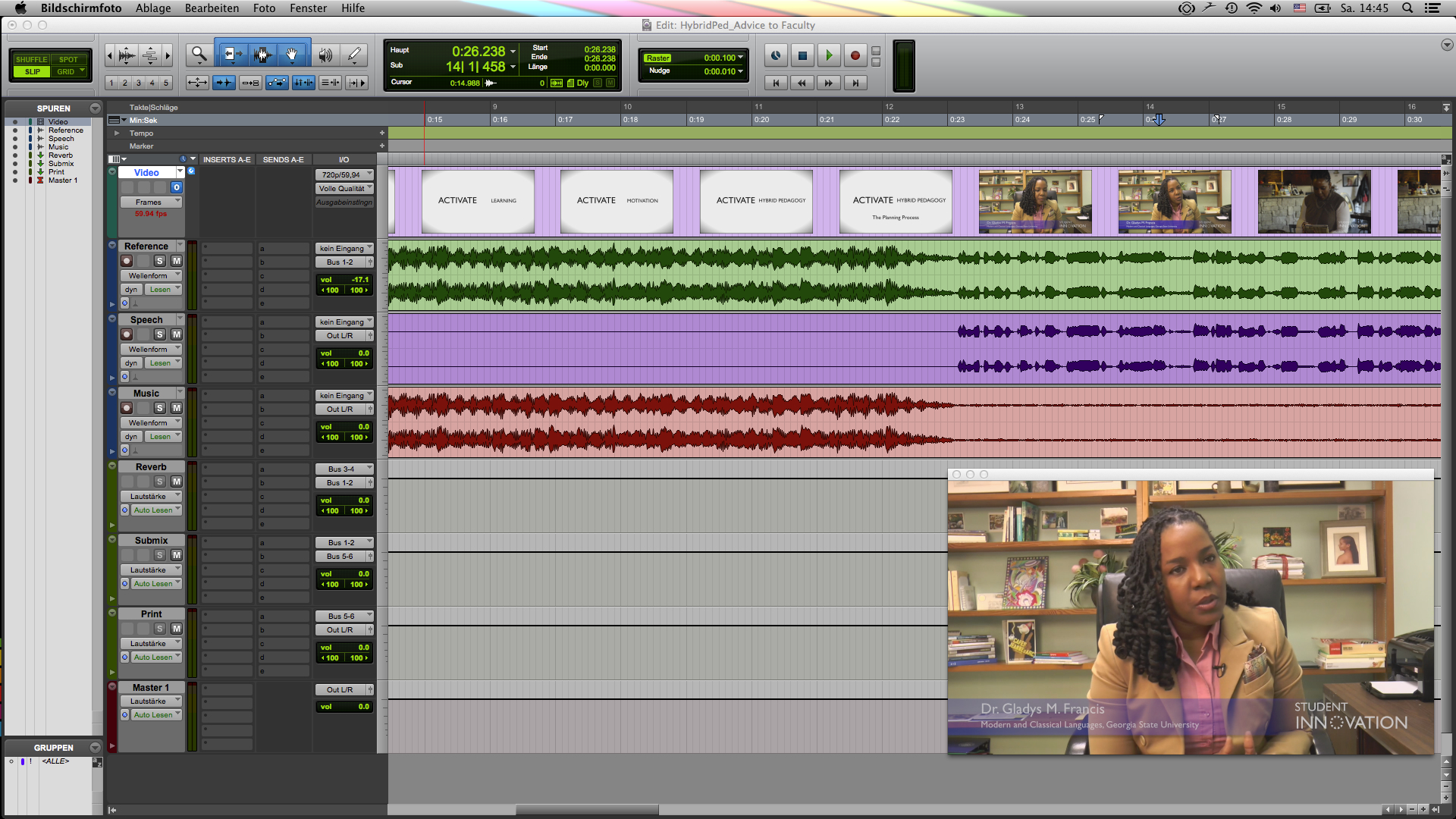
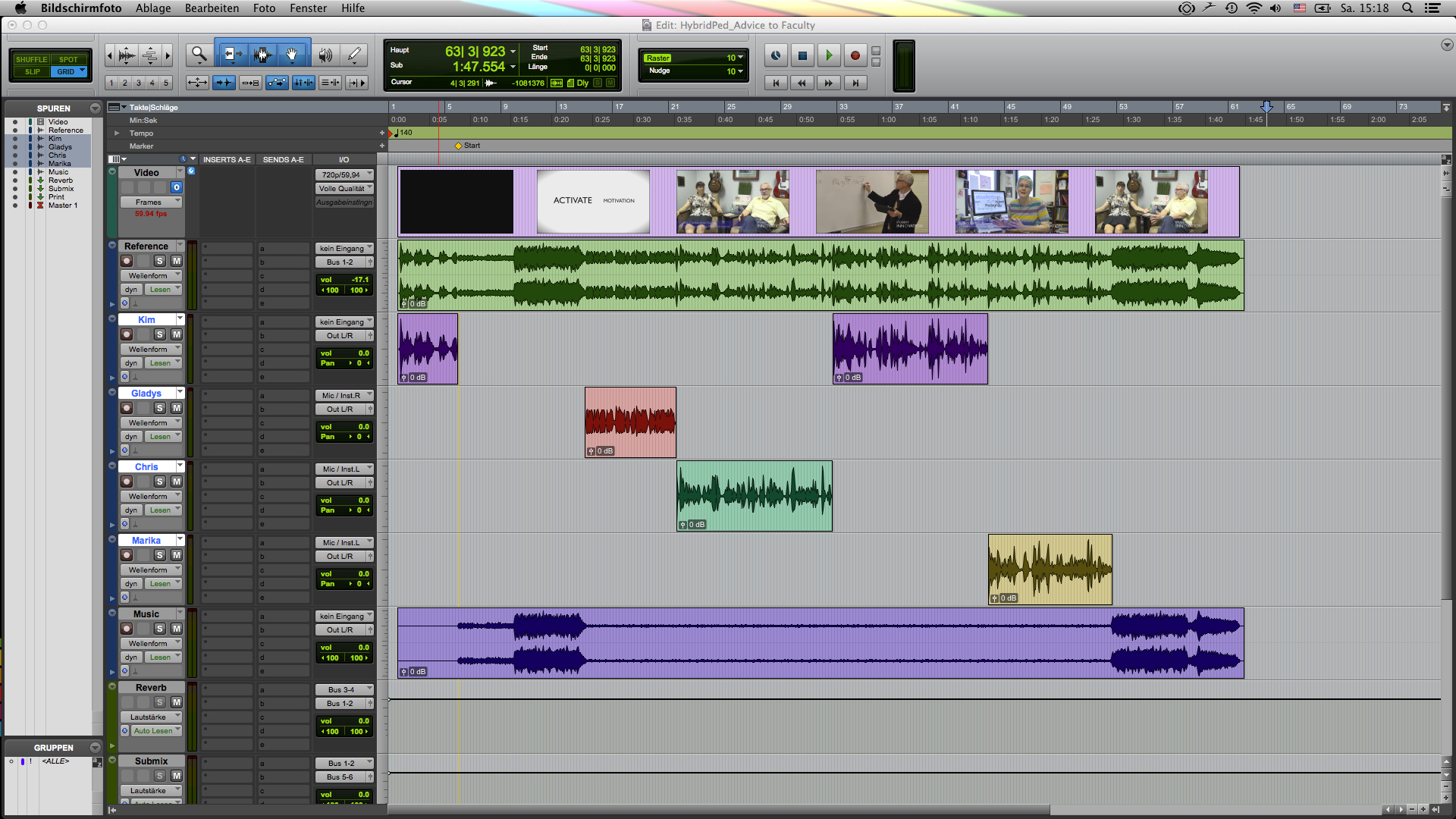
What I already know is that since we’re dealing with four speakers (three women and one man), we’re going to run into issues if we process the voice track as a whole. Each speaker will have a different timbre, so if the processing works for one speaker, it will surely not work for the other three. Therefore, I cut the voice track and created new audio tracks, so that I can process each speaker individually. For the background music we’re relying on a pre-recorded music track with a Creative Commons license, which means it is freely available, and also already processed. So, no need to add further processing to it. However, what you surely want to do when you have music as part of a video interview is to have the automatically decrease in volume when there is speech, and then increase again during pauses or sections where there is no speech. What we want to accomplish is a consolidated listening experience from start to finish. This automatic volume adjustment is called “ducking”. If you look at the image below, you will see the music track in purple at the bottom. Notice, how the waveform is larger when nobody speaks (i.e. relative to the four tracks above you’re seeing above the purple track), and much smaller overall when there is speech.
Now that this is done, we can start dealing with the biggest issue: noise. I’m sure most of you have experienced the kind of background noise I’m talking about. Take for example a video recorded on a smart phone and instantly uploaded to YouTube. In the background you might hear a hum, or hiss, that’s quite noticeable throughout the entire video, so much so that it can distract you from focusing on the content. One of the most common background noises is the so-called 60 Hz cycles hum, caused by electro-magnetic vibrations. Let’s hear an example of it in isolation.
There are two ways to deal with these kind of unwanted noise problems. The first is to use an equalizer, which is nothing more than a frequency-based volume control at the end of the day. Today’s digital equalizers commonly include a visual graph of the entire range of frequencies we can process. That makes it easy to locate the 60 Hz frequency by turning the frequency control knob, and then notching it out with the gain knob. Keep in mind, however, that you want to use a very narrow bandwidth so that the equalizer only applies processing to the frequency in question. The so-called Q-knob allows you to narrow the bandwidth. The other way is to use more specialized tools for that purpose. The benefit of using a specialized tool such as the NF 575 noise shaper which you’re seeing in the screenshot below, is that these types of plugins automatically take into account the fact that background noises such as buzz and hum not only occur at the core frequency, but they also translate up the frequency range in regular intervals, which are called harmonics. If you use a standard equalizer, you would have to find the upper harmonics, that contribute to the noise, manually. Specialized tools will do that work for you. Notice the visual graph in the plugin window below, and you will notice that it is not just the core frequency that is notched (in yellow), but also the corresponding harmonics (in green, blue, and purple). In addition, when processing voice material you want to make sure to filter out all the audio information that lives below the frequency range of the human voice, which is usually between 75 hz to 12,000 KHz. Microphones have a much wider frequency range than what the human voice uses, which means that a microphone will pick up more information than is needed. For Kim’s vocal track, that meant cutting away all the audio information below 100 Hz (colored in gray) since her voice doesn’t use that frequency range at all. Be careful, though, when you use filters. You don’t want to set the filter too high. 75-100 Hz is usually good for male voices, 100-125 Hz for female voices.
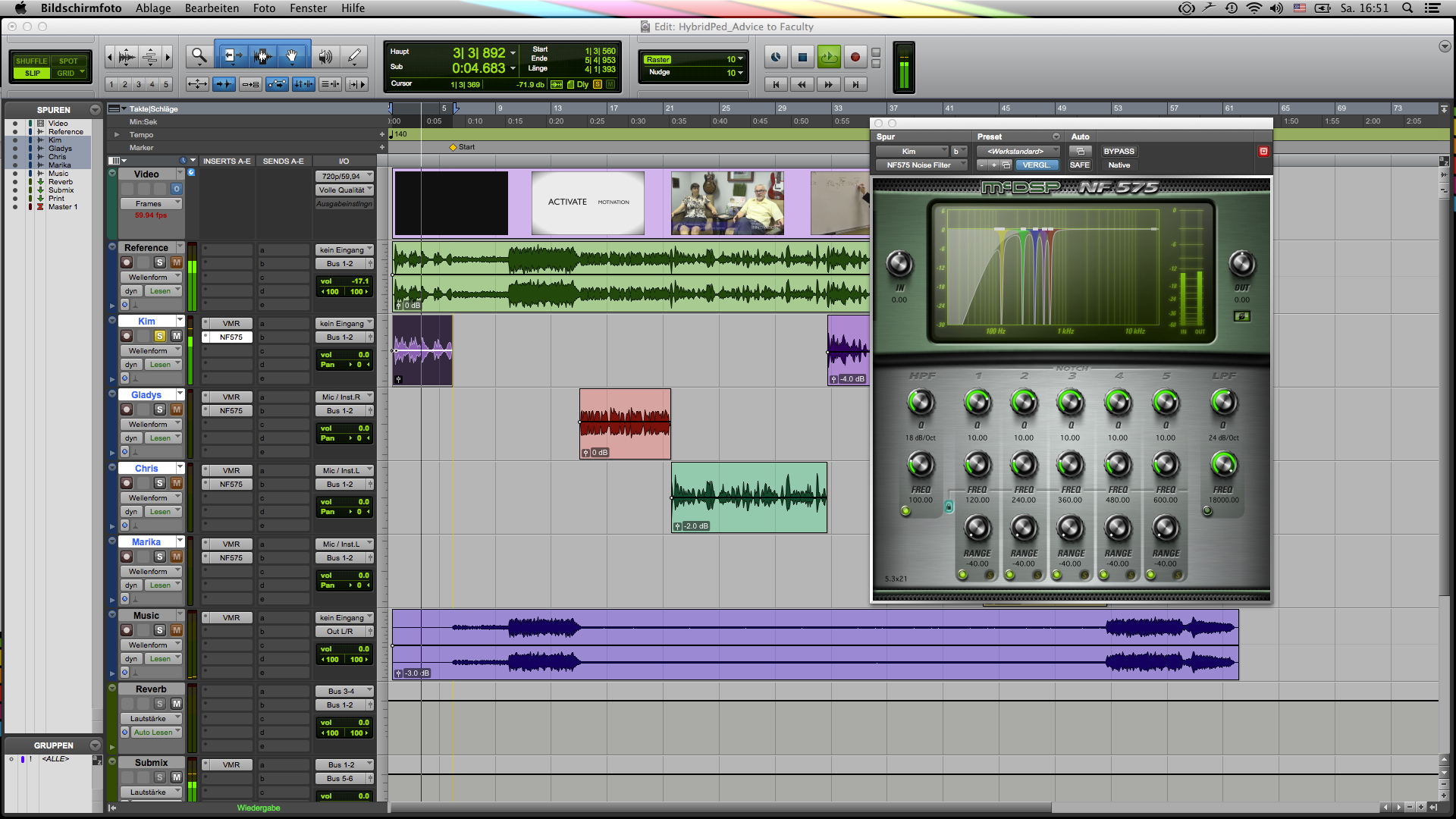
As you can see (you might have to zoom in a bit), the first frequency (no# 1) is set to 120Hz. With a simple press of a button, the other four frequency bands automatically settle on the remaining harmonic frequencies above the core frequency. Let’s hear the difference:
With noise:
Without noise:
You can do the same thing with a regular equalizer. You just need to make sure that you find those upper harmonics.
To conclude the first step, I did some minor level adjustments so that all the speakers are roughly equal volume.
2. Using the Equalizer
Once I was happy with the results, I moved on to applying some equalization of the signals. I knew that I would be using some compression (basically automatic gain adjustment) later on to smooth out the overall volume of the tracks, and to avoid audio spikes from happening. Therefore, I applied some equalization before the compression because I didn’t want the compressor to react to frequency content that I didn’t consider relevant.

I understand that this whole window must seem confusing, but what I want you to look at is in the lower right corner. There you see a visual representation of the equalizer. In almost every recording, there are parts of the audio signal that become problematic when multiple signals are played back together. Then, certain frequencies start to compete with one another. Perfect example is a vocal and a guitar. Both instruments use a similar frequency range. Within that frequency range, however, there are parts which really help the guitar to be heard while others really help the vocal when played together. Therefore, it’s a common practice to cut out some frequencies from the guitar to make room for the vocal, and vice versa.
But moving back to the work at hand. I carved out some unnecessary frequencies to make the vocal sit better with the music in the background.
3. Compression
There are entire books that discuss compression, so I won’t be really going into details. However, I’d like to give you at least a general idea about compression and what it does: let’s say you’re driving in a car with your mother. Your favorite song is playing on the radio, but there are parts in the song that your mother finds way too loud. So, anytime she thinks the music crosses a volume level she isn’t comfortable with she automatically reaches for the volume knob, turns it down and brings it back up in accordance with her overall volume preference. An audio compressor works quite similarly. It’s automatic volume control. A compressor usually consists of four parameters: attack, release, threshold, and ratio. Going back to the car analogy: attack is the amount of time it takes your mother to reach for the volume knob on the radio, release is the amount of time it takes her to bring the volume back up once each loud part of the song is over, threshold is the volume level above which your mother freaks out because it’s too loud, and ratio translates into the amount of volume that she attenuates. In essence, a compressor is a tool that you can use to deal with sudden peaks in the audio signal, thereby smoothing the perceived performance.
Coming back to the video, take a look at the following image, and notice the wave form in the yellow-colored block:
As you can see, there are a couple of spikes in the signal. Using a compressor can help taming those audio signal peaks in order to create a more even performance. Below is an image of a compressor, the CLA-2A, which I used to level out the vocal performances.

4. Taking care of Sibilance
Oftentimes, especially with vocal performances, we also encounter unwanted high frequencies that occur when words are spoken that contain S’s, F’s, P’s, and T’s. The most common issue is with sibilant S’s. To deal with those unwanted kinds of sibilant hissing noises, I use a specialized compressor, called a “de-esser.” This particular compressor can be set only to those sibilant frequencies without affecting the rest of the audio signal. In the screenshot below, you see the de-esser on the right sight, providing a visual graph that shows the frequency which is being attenuated:
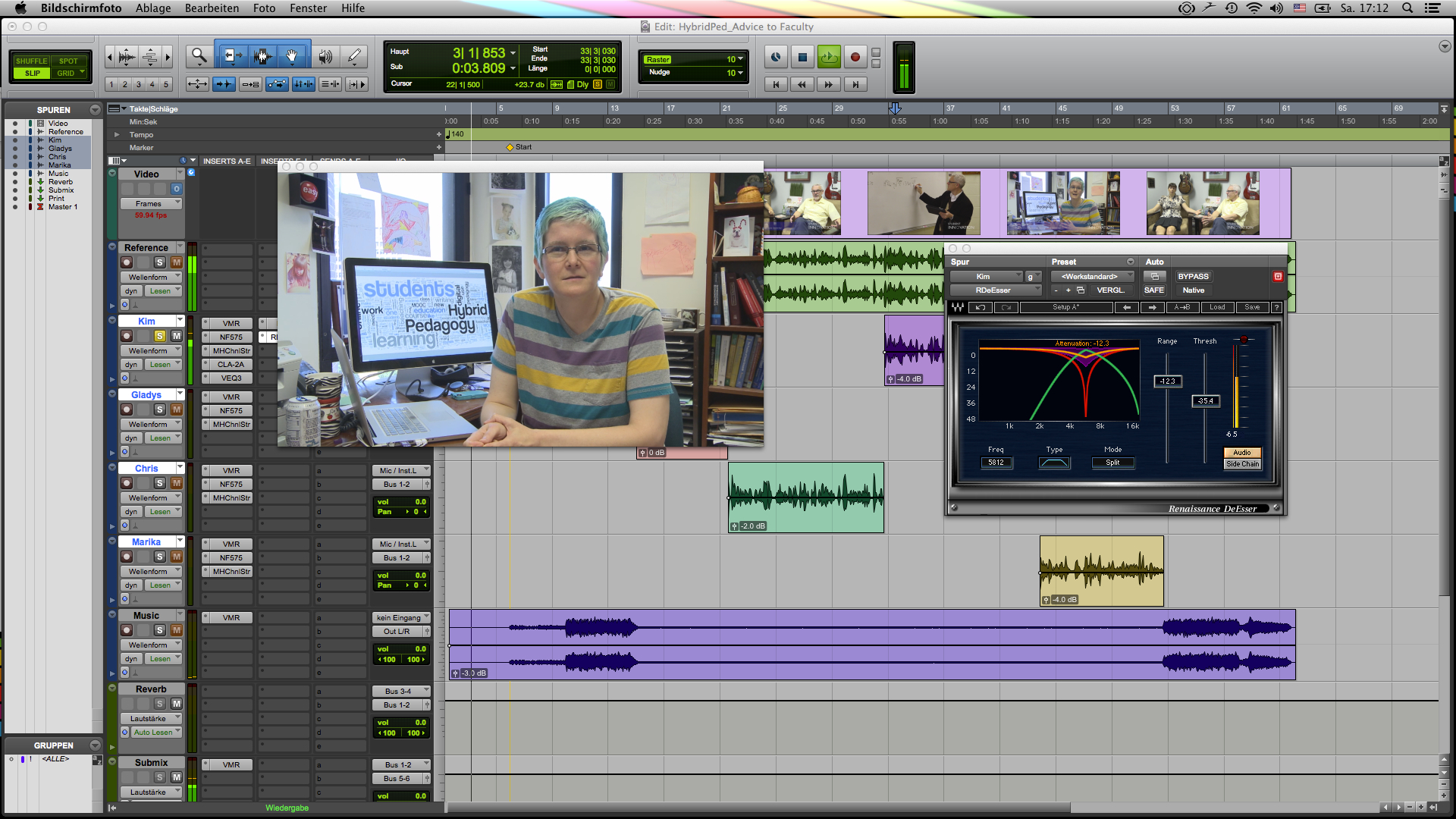
If you look closely, you’ll notice that the top left of the plugin contains a visual representation of the frequency spectrum. Below there are three controls. I’m using the “Freq” button to set the desired frequency where the sibilant noises occur, in this case 5812 Hz. Then I lower the threshold on the right until the S’s are being attenuated. Watch out, though. If you set the threshold too low, then too much of the sibilance is lost, and the speaker will appear to have a lisp.
Let’s hear what the de-esser does to the signal. Listen closely to ‘ch’ in the word “teaching” and the ‘s’ in “course”:
Without De-essing:
With De-essing:
The key is not to get rid of the sibilance entirely. Then it wouldn’t sound natural anymore. But you do want to tame those moments of sibilance a bit.
5. Limiting
As a last step, I used some limiting to bring the entire audio signal to a more reasonable listening level overall. Limiters are special kinds of compressors that usually come into play at the end of a chain of processing to prevent audio signals from clipping and distorting. Here is a great explanation taken from Mediacollege.com of what a limiter does and how it differs from a regular compressor:
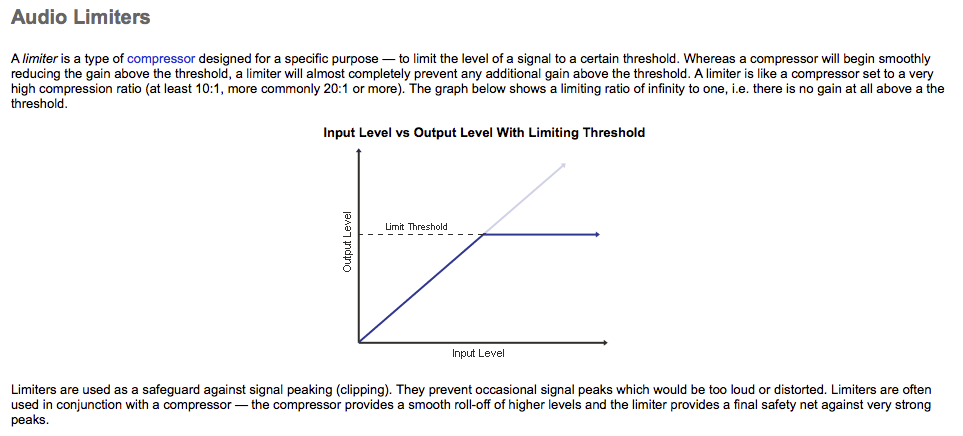
And that pretty much concludes what I’ve done to the audio signals. We will be showcasing the videos at our end of the semester showcase.
I wish you all a great Spring Break!
Best,
Thomas
thanks for sharing about audio post production, your post is very useful, big thanks
interesting complex technologies behind the comfort of good and clean audio output 😀 thanks for sharing! 😀