
 To kick off the year’s blogging, I thought I would highlight one of the lesser-known SIF projects, the Almanac Archive. The Almanac Archive seeks to build a virtual collection of British almanacs published between 1750-1850. These incredibly popular texts (along with the bible one of the most likely books for any given person to read and use) are incredibly rich and diverse sources for scholarship in many fields. Designed to be useful, almanacs included a vast array of information about civic and political events (the dates of university terms, holidays and feast days, significant historical events) and the natural world (including tide tables, zodiac charts, eclipses). And used they were. One of the neat things about almanacs is that they often show signs of active use and engagement, in the form of reader annotations and marginalia, noting for instance particularly unusual weather events, which days crops were planted or harvested, and otherwise interacting with and personalizing the text.
To kick off the year’s blogging, I thought I would highlight one of the lesser-known SIF projects, the Almanac Archive. The Almanac Archive seeks to build a virtual collection of British almanacs published between 1750-1850. These incredibly popular texts (along with the bible one of the most likely books for any given person to read and use) are incredibly rich and diverse sources for scholarship in many fields. Designed to be useful, almanacs included a vast array of information about civic and political events (the dates of university terms, holidays and feast days, significant historical events) and the natural world (including tide tables, zodiac charts, eclipses). And used they were. One of the neat things about almanacs is that they often show signs of active use and engagement, in the form of reader annotations and marginalia, noting for instance particularly unusual weather events, which days crops were planted or harvested, and otherwise interacting with and personalizing the text.
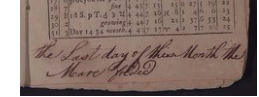
recording the birth of a horse (http://pudl.princeton.edu/objects/bk128b63x) (detail)
The goal of the Almanac Archive is to make a large number of these texts- and the annotations they contain — accessible to scholars in a single location. At the core of the project is building a database that will link to digitized almanacs owned by research libraries in the UK and North America, with the goal of providing digital access and finely-tuned search capabilities to negotiate and use this assemblage.
The project is cool on a number of levels, but what I want to focus on here is how it will cut across institutional collections to create a pan-institutional resource. A lot of institutions own these books -they were, after all, extremely common – but to the extent they have been digitized their digital surrogates are spread out in widely different internet archives. For instance here and here. Do any of these particular almanacs contain annotations? The only way to know is to skim each individually.
Even with the help of google, locating digitized almanac, let alone collating them, is no small task, and one of the virtues of a content-focused archive such as the Almanac Archive is that it can bring specific types of texts into a single collection, even though the originals and their surrogates are widely scattered. This in and of itself is no small help to researchers, but the Archive is not just a link farm. The database we’ll be hosting will allow people to search through multiple collections simultaneously, allowing you to easily view, say, all the digitized almanacs from a specific year, or specific title, or which contain information specific to a particular region in Britain and so on. Moreover, in keeping with the Archive’s emphasis on how readers interacted with their almanacs, you’ll also be able to search for specific types of annotations across all the almanacs in the database. So, if you want to look for children’s drawings, notes about the weather or personal finances, you’ll be able to do so in one fell swoop. To my mind, this is the answer to a question posed at our first team meeting last week: what value can a digital archive add to a physical archive, beyond ease of access? The archive will make searches possible across institutional boundaries and in ways that exceed are not possible using the metadata available in conventional card cataloging and digital surrogates.
It’s also going involve a considerable amount of active curation, which brings me back to my favorite topic, the SIF and graduate education. Annotations will need to be transcribed, bibliographic information will need to be compiled, and real critical thought and attention will be required in order to generate the database. Who will perform this labor? If you ask me, this is exactly the kind of work that graduate students could perform in a refocused graduate humanities curriculum that places greater emphasis on collective, long-term project work and on producing MA’s and PhD’s with real experience in the digital humanities.